- Published on
pytorch - fashion MNIST 분류 실습
- Author

- Name
- yceffort
pytorch를 활용해서 옷 이미지를 구별하는 예제를 해봤었는데, 다시 한번 복습하는 차원에서 기본적인 기능으로 해보려고 한다.
1. 데이터셋 준비
import torch
from torchvision import datasets, transforms
import helper
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# Download and load the training data
trainset = datasets.FashionMNIST('~/.pytorch/F_MNIST_data/', download=True, train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# Download and load the test data
testset = datasets.FashionMNIST('~/.pytorch/F_MNIST_data/', download=True, train=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)
먼저 데이터를 받기전에, 해당 데이터를 torch tensor로 바꾸고, Normalize할 수 있는 transform을 준비했다. 그리고 굳이 test set과 train set을 손수 나누지 않아도 저렇게 구별할 수 있게 해주었다. 그리고 각각의 데이터를 dataloader에 실어 넣었다.
이미지를 잠깐 살펴보기 위하여, imshow라는 메소드를 하나 만들었다.
def imshow(image, ax=None, title=None, normalize=True):
"""Imshow for Tensor."""
if ax is None:
fig, ax = plt.subplots()
image = image.numpy().transpose((1, 2, 0))
if normalize:
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image = std * image + mean
image = np.clip(image, 0, 1)
ax.imshow(image)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.tick_params(axis='both', length=0)
ax.set_xticklabels('')
ax.set_yticklabels('')
return ax
image, label = next(iter(trainloader))
imshow(image[0,:]);

이게 옷인가 싶은 모양이지만 (..) 암튼 원피스겠지
2. 네트워크 만들기
만들어볼 네트워크는 아래와 같다.
- input layer: 28 * 28 = 764
- hidden layer: 2개, 각각 256, 128 개의 뉴런을 갖고 있음
- output layer: 10개 (구별할 옷이 열 종류)
- Adam Optimizer 와 NLLLoss 활용
class Classifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 64)
self.fc4 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(x.shape[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = F.log_softmax(self.fc4(x), dim=1)
return x
3. 네트워크 훈련하기
model = Classifier()
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
epochs = 20
for e in range(epochs):
running_loss = 0
for images, labels in trainloader:
# 모델에서 훈련
result = model(images)
# 오차 계산
loss = criterion(result, labels)
# 초기화
optimizer.zero_grad()
# 역전파
loss.backward()
# 스텝
optimizer.step()
# 오차값을 총 오차에 더함
running_loss += loss.item()
else:
print(f"Training loss: {running_loss/len(trainloader)}")
Training loss: 0.5118639363504168
Training loss: 0.3933752618714182
Training loss: 0.35750402640432183
Training loss: 0.33432440921219425
Training loss: 0.31787964060648416
Training loss: 0.3047505217606325
Training loss: 0.29022969397654663
Training loss: 0.28075202265337335
Training loss: 0.27226868114555314
Training loss: 0.26422357173966193
Training loss: 0.2592774396702679
Training loss: 0.25201891171636737
Training loss: 0.24683423794265877
Training loss: 0.24124097148540305
Training loss: 0.23825587014923852
Training loss: 0.2335602915538018
Training loss: 0.224308533554297
Training loss: 0.22240888378592824
Training loss: 0.21599145372634504
Training loss: 0.21485247272354707
4. 결과
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
dataiter = iter(testloader)
images, labels = dataiter.next()
img = images[0]
img = img.resize_(1, 784)
ps = torch.exp(model(img))
view_classify(img.resize_(1, 28, 28), ps, version='Fashion')

5. 총 accuracy 구하기
model = Classifier()
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
epochs = 30
steps = 0
train_losses, test_losses = [], []
for e in range(epochs):
running_loss = 0
for images, labels in trainloader:
optimizer.zero_grad()
log_ps = model(images)
loss = criterion(log_ps, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# for 문이 끝나면 실행한다.
else:
test_loss = 0
accuracy = 0
# Turn off gradients for validation, saves memory and computations
# 자동 미분을 꺼서 pytorch가 쓸 떼 없는 짓을 안하게 한다. (어차피 test set에서 하는 작업이므로)
with torch.no_grad():
for images, labels in testloader:
log_ps = model(images)
test_loss += criterion(log_ps, labels)
# 로그 확률에 지수 적용
ps = torch.exp(log_ps)
# topk는 k번째로 큰 숫자를 찾아내는 것이다.
# dim=1 는 dimension을 의미한다.
top_p, top_class = ps.topk(1, dim=1)
# labels를 top_class와 똑같은 형태로 만든다음에, 얼마나 같은게 있는지 확인한다.
equals = top_class == labels.view(*top_class.shape)
# equals를 float으로 바꾸고 평균 정확도를 구한다.
accuracy += torch.mean(equals.type(torch.FloatTensor))
train_losses.append(running_loss/len(trainloader))
test_losses.append(test_loss/len(testloader))
print("Epoch: {}/{}.. ".format(e+1, epochs),
"Training Loss: {:.3f}.. ".format(running_loss/len(trainloader)),
"Test Loss: {:.3f}.. ".format(test_loss/len(testloader)),
"Test Accuracy: {:.3f}".format(accuracy/len(testloader)))
Epoch: 1/30.. Training Loss: 0.521.. Test Loss: 0.461.. Test Accuracy: 0.833
Epoch: 2/30.. Training Loss: 0.395.. Test Loss: 0.429.. Test Accuracy: 0.839
Epoch: 3/30.. Training Loss: 0.357.. Test Loss: 0.393.. Test Accuracy: 0.862
Epoch: 4/30.. Training Loss: 0.334.. Test Loss: 0.388.. Test Accuracy: 0.863
Epoch: 5/30.. Training Loss: 0.318.. Test Loss: 0.380.. Test Accuracy: 0.867
Epoch: 6/30.. Training Loss: 0.303.. Test Loss: 0.367.. Test Accuracy: 0.871
Epoch: 7/30.. Training Loss: 0.292.. Test Loss: 0.386.. Test Accuracy: 0.869
Epoch: 8/30.. Training Loss: 0.285.. Test Loss: 0.371.. Test Accuracy: 0.879
Epoch: 9/30.. Training Loss: 0.274.. Test Loss: 0.357.. Test Accuracy: 0.878
Epoch: 10/30.. Training Loss: 0.274.. Test Loss: 0.377.. Test Accuracy: 0.876
Epoch: 11/30.. Training Loss: 0.261.. Test Loss: 0.369.. Test Accuracy: 0.871
Epoch: 12/30.. Training Loss: 0.255.. Test Loss: 0.357.. Test Accuracy: 0.881
Epoch: 13/30.. Training Loss: 0.251.. Test Loss: 0.385.. Test Accuracy: 0.873
Epoch: 14/30.. Training Loss: 0.248.. Test Loss: 0.405.. Test Accuracy: 0.875
Epoch: 15/30.. Training Loss: 0.240.. Test Loss: 0.368.. Test Accuracy: 0.882
Epoch: 16/30.. Training Loss: 0.232.. Test Loss: 0.364.. Test Accuracy: 0.883
Epoch: 17/30.. Training Loss: 0.230.. Test Loss: 0.413.. Test Accuracy: 0.872
Epoch: 18/30.. Training Loss: 0.229.. Test Loss: 0.384.. Test Accuracy: 0.878
Epoch: 19/30.. Training Loss: 0.221.. Test Loss: 0.376.. Test Accuracy: 0.883
Epoch: 20/30.. Training Loss: 0.217.. Test Loss: 0.443.. Test Accuracy: 0.867
Epoch: 21/30.. Training Loss: 0.217.. Test Loss: 0.382.. Test Accuracy: 0.880
Epoch: 22/30.. Training Loss: 0.212.. Test Loss: 0.403.. Test Accuracy: 0.880
Epoch: 23/30.. Training Loss: 0.209.. Test Loss: 0.403.. Test Accuracy: 0.879
Epoch: 24/30.. Training Loss: 0.209.. Test Loss: 0.398.. Test Accuracy: 0.881
Epoch: 25/30.. Training Loss: 0.202.. Test Loss: 0.406.. Test Accuracy: 0.880
Epoch: 26/30.. Training Loss: 0.200.. Test Loss: 0.390.. Test Accuracy: 0.882
Epoch: 27/30.. Training Loss: 0.194.. Test Loss: 0.405.. Test Accuracy: 0.878
Epoch: 28/30.. Training Loss: 0.195.. Test Loss: 0.415.. Test Accuracy: 0.879
Epoch: 29/30.. Training Loss: 0.193.. Test Loss: 0.418.. Test Accuracy: 0.883
Epoch: 30/30.. Training Loss: 0.187.. Test Loss: 0.412.. Test Accuracy: 0.879
6. loss 확인해보기
%matplotlib inline
%config InlineBackend.figure_format='retina'
import matplotlib.pyplot as plt
plt.plot(train_losses, label='training loss')
plt.plot(test_losses, label='Validation loss')
plt.legend(frameon=False)

training loss는 점차 감소하지만, validation loss는 널뛰기 하고 있다. 이 말인 즉슨, 현재 overfitting 현상이 일어나고 있는 것이다.
7. dropout
드롭아웃은 Overfitting을 방지하기 위한 방법이다.
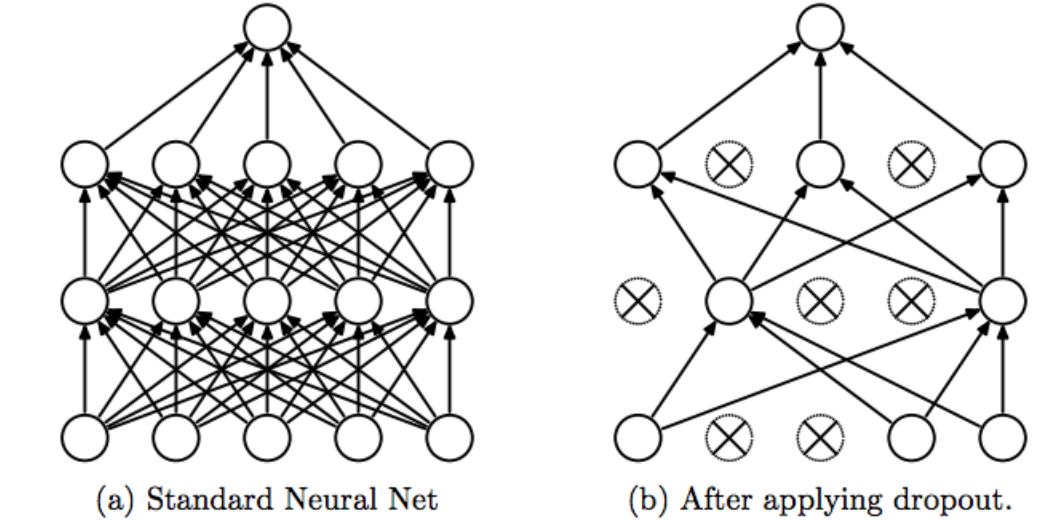
일부 노드들을 훈련에 참여시키지 않고 몇개의 노드를 끊어서, 남은 노드들을 통해서만 훈련시키는 방식이다. 이 때 끊어버리는 노드는 랜덤으로 선택한다. pytorch에서는 기본값이 0.5 다. 즉 절반의 노드를 dropout하고 계산한다. 이렇게 함으로써, training하는 과정에서 Overfitting이 발생하지 않게 할 수 있다.
class Classifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 64)
self.fc4 = nn.Linear(64, 10)
# 0.2정도를 무작위로 골라 dropout한다.
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
x = x.view(x.shape[0], -1)
x = self.dropout(F.relu(self.fc1(x)))
x = self.dropout(F.relu(self.fc2(x)))
x = self.dropout(F.relu(self.fc3(x)))
# output은 dropout하면 안된다..
x = F.log_softmax(self.fc4(x), dim=1)
return x
dropout은 주의해야할 것이, training 과정에서만 이루어져야 한다는 것이다.
model = Classifier()
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
epochs = 30
steps = 0
train_losses, test_losses = [], []
for e in range(epochs):
running_loss = 0
for images, labels in trainloader:
optimizer.zero_grad()
log_ps = model(images)
loss = criterion(log_ps, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
else:
test_loss = 0
accuracy = 0
with torch.no_grad():
# test 과정에 들어간다. dropout을 안하게 된다.
# 정확하게 말하면, dropout 하는 비율이 0이 된다.
model.eval()
for images, labels in testloader:
log_ps = model(images)
test_loss += criterion(log_ps, labels)
ps = torch.exp(log_ps)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor))
# 다시 트레이닝 과정으로 돌아간다.
model.train()
train_losses.append(running_loss/len(trainloader))
test_losses.append(test_loss/len(testloader))
print("Epoch: {}/{}.. ".format(e+1, epochs),
"Training Loss: {:.3f}.. ".format(train_losses[-1]),
"Test Loss: {:.3f}.. ".format(test_losses[-1]),
"Test Accuracy: {:.3f}".format(accuracy/len(testloader)))
Epoch: 1/30.. Training Loss: 0.602.. Test Loss: 0.508.. Test Accuracy: 0.818
Epoch: 2/30.. Training Loss: 0.482.. Test Loss: 0.454.. Test Accuracy: 0.835
Epoch: 3/30.. Training Loss: 0.450.. Test Loss: 0.429.. Test Accuracy: 0.848
Epoch: 4/30.. Training Loss: 0.434.. Test Loss: 0.418.. Test Accuracy: 0.851
Epoch: 5/30.. Training Loss: 0.416.. Test Loss: 0.431.. Test Accuracy: 0.852
Epoch: 6/30.. Training Loss: 0.413.. Test Loss: 0.399.. Test Accuracy: 0.855
Epoch: 7/30.. Training Loss: 0.405.. Test Loss: 0.394.. Test Accuracy: 0.856
Epoch: 8/30.. Training Loss: 0.397.. Test Loss: 0.386.. Test Accuracy: 0.858
Epoch: 9/30.. Training Loss: 0.392.. Test Loss: 0.412.. Test Accuracy: 0.855
Epoch: 10/30.. Training Loss: 0.388.. Test Loss: 0.380.. Test Accuracy: 0.865
Epoch: 11/30.. Training Loss: 0.383.. Test Loss: 0.376.. Test Accuracy: 0.865
Epoch: 12/30.. Training Loss: 0.375.. Test Loss: 0.392.. Test Accuracy: 0.863
Epoch: 13/30.. Training Loss: 0.380.. Test Loss: 0.382.. Test Accuracy: 0.863
Epoch: 14/30.. Training Loss: 0.374.. Test Loss: 0.370.. Test Accuracy: 0.876
Epoch: 15/30.. Training Loss: 0.368.. Test Loss: 0.385.. Test Accuracy: 0.864
Epoch: 16/30.. Training Loss: 0.371.. Test Loss: 0.371.. Test Accuracy: 0.871
Epoch: 17/30.. Training Loss: 0.358.. Test Loss: 0.392.. Test Accuracy: 0.861
Epoch: 18/30.. Training Loss: 0.354.. Test Loss: 0.371.. Test Accuracy: 0.872
Epoch: 19/30.. Training Loss: 0.354.. Test Loss: 0.373.. Test Accuracy: 0.873
Epoch: 20/30.. Training Loss: 0.353.. Test Loss: 0.386.. Test Accuracy: 0.867
Epoch: 21/30.. Training Loss: 0.361.. Test Loss: 0.388.. Test Accuracy: 0.867
Epoch: 22/30.. Training Loss: 0.350.. Test Loss: 0.385.. Test Accuracy: 0.869
Epoch: 23/30.. Training Loss: 0.353.. Test Loss: 0.371.. Test Accuracy: 0.869
Epoch: 24/30.. Training Loss: 0.343.. Test Loss: 0.368.. Test Accuracy: 0.872
Epoch: 25/30.. Training Loss: 0.351.. Test Loss: 0.378.. Test Accuracy: 0.875
Epoch: 26/30.. Training Loss: 0.339.. Test Loss: 0.371.. Test Accuracy: 0.872
Epoch: 27/30.. Training Loss: 0.351.. Test Loss: 0.372.. Test Accuracy: 0.875
Epoch: 28/30.. Training Loss: 0.350.. Test Loss: 0.375.. Test Accuracy: 0.871
Epoch: 29/30.. Training Loss: 0.353.. Test Loss: 0.391.. Test Accuracy: 0.875
Epoch: 30/30.. Training Loss: 0.340.. Test Loss: 0.385.. Test Accuracy: 0.876
다시 결과를 보자.
plt.plot(train_losses, label='Training loss')
plt.plot(test_losses, label='Validation loss')
plt.legend(frameon=False)

dropout이 overfitting을 방지해 주는 것을 알 수 있다.