- Published on
V8 엔진에 대해 가볍게 살펴보기
- Author

- Name
- yceffort
대부분의 프론트엔드 개발자들은 V8이라는 용어를 들어본 적이 있을 것이다. V8은 구글에서 만든 오픈소스 자바스크립트 및 웹 어셈블리 엔진으로, C++ 로 작성 되어있으며 현재 크롬과 Nodejs 등에서 사용되고 있다. V8의 중요한 역할 중 하나는 generational (데이터의 시간에 따라서 정렬한다는 뜻인데, 정확히 뭐라고 표현해야 할지 모르겠다) 하면서도 매우 정확한 가비지 콜렉션이다. 메모리를 많이 사용하지 않더라도, 자바스크립트가 더 이상 필요하지 않은 객체를 수집하도록 최적화 되어 있다. 이 외에도 V8은 역사적으로 자바스크립트의 속도를 느리게 만드는 고유의 기능성을 개선하기 위해 일련의 다른 툴과 feature들을 사용한다. 이 글에서 이러한 도구 (Ignition 과 TurboFan)와 다양한 기능에 대해서 알아보고자 한다. 그 외에도 V8의 내부 기능, 컴파일 및 가비지 콜렉션 절차, 단일 스레드 특성 등의 기본 특성을 알아보고자 한다. 기회가 된다면, 정말 V8을 코드 레벨로도 살펴볼 수 있었으면 좋겠다.
기초부터 살펴보기
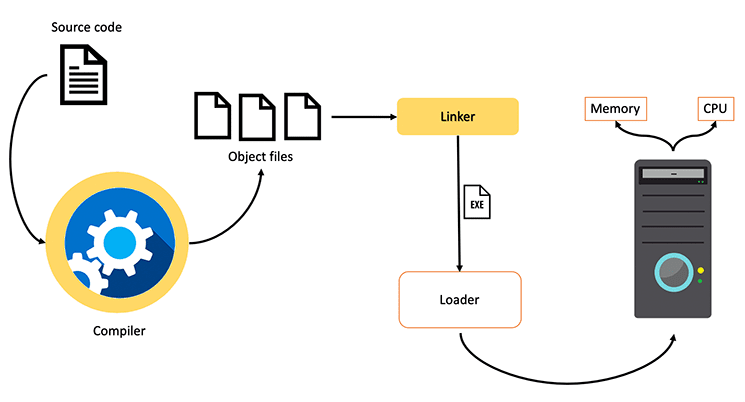
기계 코드 (Machine code)는 어떻게 동작할까? 기계 코드란 메모리의 특정부분에서 실행될 수 있는 매우 저수준의 언어 명령의 집합이다. C++ 를 기준으로 그 과정을 묘사해보자면 아래와 같다.
더 나아가기전에, 자바스크립트의 interpretation 과 는 다른 컴파일 과정이라는 것에 대해 알아볼 필요가 있다. 컴파일러는 프로세스가 끝날 때 전체 프로그램을 생성하는 반면, interpreter는 instruction (자바스크립트의 스크립트와 같은)을 읽고 실행 가능한 명령으로 말 그대로 번역하여 그 일을 하는 프로그램으로 자체 동작하게 된다.
이러한 interpretation 과정은 즉시 (인터프리터가 현재 명령 구문만 분석하고 실행) 이루어지거나 완전히 구문 분석을 마친뒤에 (인터프리터가 기계명령을 진행하기 전에 스크립트 전체를 완전히 번역할때) 모두 발생할 수 있다.
그림으로 돌아가서 다시 보면, 컴파일 프로세스는 일반적으로 알려져 있는 것처럼 소스코드로부터 시작된다. 코드를 구현하고, 이를 저장한 뒤에 실행한다. 컴파일러는 여느 프로그램처럼 머신에서 실행된다. 그런 다음 모든 코드를 살펴보고 객체 파일을 생성한다. 이러한 파일은 기계 코드다. 특정 컴퓨터에서 실행되는 최적화된 코드이므로 다른 OS 에서 이를 활용 할 때는 다른 컴파일러를 사용해야 한다.
그러나 이를 위해 별도의 객체 파일을 실행할 수는 없으므로, .exe와 같이 실행파일 형태의 단일 파일로 결합해야 한다. 이것이 바로 링커의 일이다.
마지막으로 로더는 해당 exe 파일의 코드를 OS 의 가상메모리로 전송하는 에이전트 이다. 그리고 마침내 프로그램이 실행된다.
대부분의 경우 (은행의 메인 프레임에서 Assembly로 직접 작업하는 개발자가 아니라면) Java, C#, Ruby, Javascript 와 같은 고수준 언어로 프로그래밍을 하는데 많은 시간을 할애 한다. 언어의 수준은 높을 수록 느리다. 기계어 코드인 어셈블리언어에 가까울 수록 빨라지며, 그렇기 때문에 C와 C++이 빠르다.
성능과 별도로 V8의 주요 이점 중 하나는 ECMAScript 표준을 넘어서 C++ 도 이해 할 수 있다는 것이다.
자바스크립트의 기능은 ECMAScript를 준수한다. 그리고 V8은 이 규정을 준수하는 한편으로, 이에 제한되지 않는다.
C++ 기능을 V8에 이용할 수 있는 능력은 매우 훌륭하다. C++은 파일조작, 메모리 및 스레드 처리와 같은 OS의 특수성을 매우 능숙하게 다를 수 있는데, 이러한 기능을 자바스크립트에서도 할 수 있게 끔 구현 해 두었다.
단일 스레드
Node 개발자라면 V8의 단일 스레드 특성에 익숙할 것이다. 각 자바스크립트 실행 컨텍스트는 하나의 스레드를 가지고 있다. 물론 이러한 OS 스레드 메커니즘을 V8이 뒤에서 제어하고 있다. 복잡한 소프트웨어이고, 동시에 많은 것을 수행해야 하기 때문에 이는 둘 이상의 스레드에서 작동한다. 코드를 실행하는 메인스레드, 코드를 컴파일를 다른 스레드, 가비지를 수집하는 스레드 등이 존재할 수 있다.
그러나 V8은 각 자바스크립트 컨텍스트 마다 하나의 싱글 스레드 환경을 만들어준다. 나머지는 V8의 제어 하에 놓여져 있다.
자바스크립트 코드가 호출한 함수의 스택을 상상해보자. 자바스크립트는 각 함수를 삽입 또는 호출한 순서에 따라 한 함수를 다른 함수 위에 쌓는 (스택) 방식으로 작동한다. 각 함수의 콘텐츠에 도달하기 전까지, 다른 함수를 호출하는지를 알 수 없다. 만약 그렇게 된다면, 호출자의 바로 뒤에 호출된 함수가 스택으로 배치될 것이다. 예를 들어 콜백의 경우, 맨 끝에 놓여지게 된다.
이러한 스택의 관리와 메모리 배치가 V8의 메인 작업 중 하나다.
Ignition, Turbofan
2017년 5월에 발표된 5.9 버전 이후로, V8은 Ignition 이라고 하는 V8 인터프리터를 자바스크립트 실행 파이프라인 최 상단에 배치 하였다. 또한 더 나은 최적화 컴파일러인 Turbofan도 모습을 드러냈다.
이러한 변화는 전체적인 성능에 초점을 맞추었고, 구글 개발자들이 자바스크립트 생태계가 제기하는 빠르고 상당한 엔진의 변화를 적용할 때 구글 개발자들이 직면하는 어려움을 해결하는데 중점을 두었다. 프로젝트가 시작될 때 부터 V8 메인테이너들은 자바스크립트가 진화하는 것과 같은 속도로 V8의 성능을 향상 시킬 수 있는 좋은 방법을 찾는것에 대한 고민이 있었다. 이러한 노력 덕분에, 새엔진을 가동할 때 큰 성능의 이점을 볼 수 있다.
Hidden Classes
V8의 마법같은 요소 중 하나다. 자바스크립트는 동적 언어다. 즉 실행 되는 과정에서 새로운 속성이 추가되거나, 대체되거나, 삭제될 수 있다는 것을 의미한다. 자바나 대다수의 언어의 경우 애플리케이션 시작 이후에는 동적으로 변경될 수 없는 언어와는 다른 차이다. 이러한 특징 때문에 해시 함수를 기초로한 dictionary lookup을 수행하여 이 변수가 객체가 메모리에 할당되는 위치를 장확히 알고 있다. 그러나 이는 최종 프로세스에 많은 비용이 든다. 이에 반해 다른언어에서는 객체가 생성될 때, 암묵적인 속성 중 하나로 주소(포인터)를 받는다. 이 방법으로 이들이 메모리 어디에 위치하고 있는지, 얼마나 많은 공간을 할당해야 하는지를 정확히 알 소 있다.
그러나 자바스크립트는 아직 존재하지 않는 것을 매핑할 수 없기 때문에 이러한 방법을 적용하는 것은 불가능하다. 그리고 여기에서 hidden class를 사용한다. 이는 자바에서와 거의 동일하다. 고정된 클래스와 고유 주소를 사용하여 위치를 찾는다. 그러나 프로그램 실행전에 하는 것이 아니고, V8은 런타임 도중에, 객체의 구조에 동적인 변화가 수행될 때 마다 이를 수행한다. 아래 코드를 살펴보자.
function User(name, phone, address) {
this.name = name
this.phone = phone
this.address = address
}
자바스크립트는 프로토타입 기반의 언어이므로, User 객체를 초기화 하면 아래처럼 된다.
var user = new User('John May', '+1 (555) 555-1234', '123 3rd Ave')
그러면 V8은 hidden class를 만든다. _User0이라고가정하자.
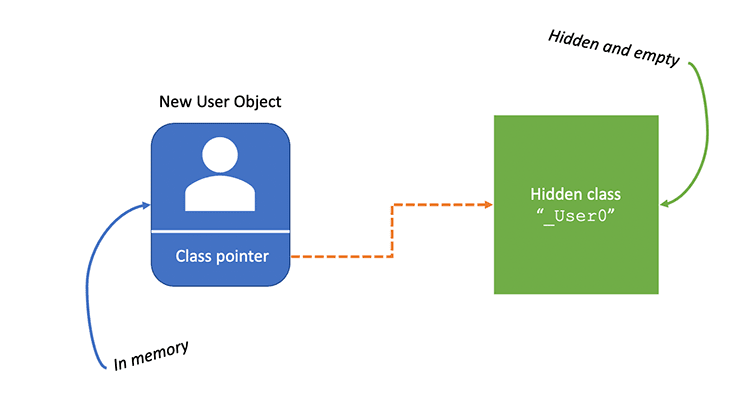
각 객체는 메모리에서 클래스 표현에 대한 참조를 가지고 있다. 이 시점에서 방금 새로운 객체를 인스턴스화 했기 때문에, 메모리 속에 숨겨진 클래스를 만들었다. 그리고 당장은 비어있다. 그리고 함수의 첫번째 줄을 실행하게 되면, 새로운 hidden class가 이전 hidden class를 기반으로 생성된다. 그리고 이를 _User1이라고 해보자.
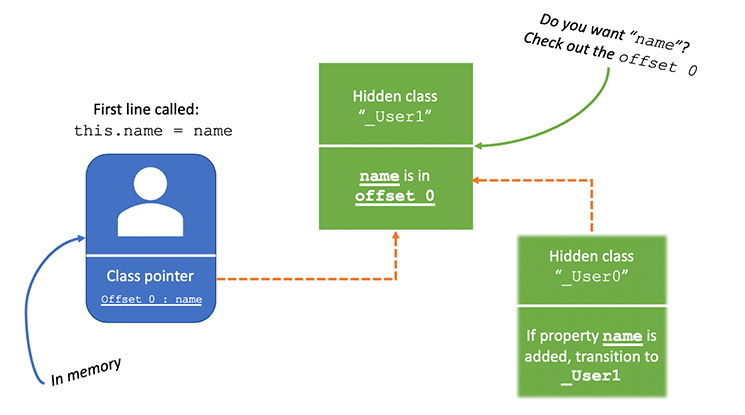
기본적으로 User의 메모리 주소는 name속성을 갖는다. 이 예제에서는, name만 가진 user를 속성으로 사용하는 것이 아니라, 매번 이렇게 할 때마다 hidden class V8이 참조로 로드된다. name 속성은 메모리 버퍼에 offset 0으로 추가되는데, 이 뜻은 첫번째 속성으로 분류된다는 것이다.
V8은 또항 transition value를 _User0 hidden class에 추가 했다. 이는 인터프리터가 User에 name속성이 추가 될 때 마다, _User0에서 _User1 로 값의 이동이 이루어 져야 한다는 것을 알려 준다.
그리고 두번째 줄이 호출되면, 같은 과정이 반복되면서 hidden class 가 생성된다.
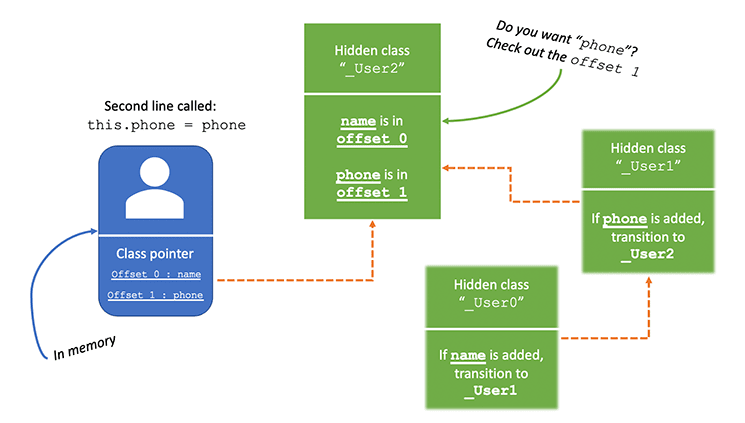
hidden class가 스택형태로 쌓여 있는 것을 볼 수 있다. 하나의 hidden class가 체이닝 형태로 값을 이어가고 있는 것을 볼 수 있다. 이 속성의 순서는 V8이 hidden class를 만드는 순서를 결정한다. 속성의 순서를 바꾼다면, 생성되는 hidden class의 순서도 바뀐다. 이러한 이유 때문에 개발자들이 가급적이면 존재하는 hidden class를 재사용하기 위해 속성의 순서를 유지하는 것이다.
인라인 캐싱
JIT 컴파일러를 사용한다면 이는 매우 익숙한 용어다. 이는 hidden class의 콘셉트와 바로 직결된다. 예를 들어, 객체를 매개변수로 하는 함수를 호출 할 때마다 V8은 이 동작을 보고, "음.. 이 객체는 이 함수에 대한 매개변수를 두번이상 성공적으로 전달했군, hidden class를 검증하는 프로세스를 다시 수행하지 않고 향후 호출을 위해 캐시에 저장해두면 어떨까?" 라는 생각을 하게 된다.
function User(name, fone, address) {
// Hidden class _User0
this.name = name // Hidden class _User1
this.phone = phone // Hidden class _User2
this.address = address // Hidden class _User3
}
User 객체가 함수의 파라미터로 두번이상 초기화 된다면, V8은 hidden class를 참고하는 것을 스킵하고 바로 속성의 offset을 참고한다. 이게 훨씬 빠르다. 그러나 항상 명심해 두어야 할 것은, 속성의 순서가 변하게 된다면 다른 hidden class를 만들게 되기 때문에 인라인 캐싱이 어려워진다.
가비지 컬렉팅
V8의 가비지 컬렉팅은 프로그램 실행 스레드와 다른 스레드에서 이뤄지기 때문에, 프로그램 실행에 영향을 미치지 않는다. V8은 mark-and-sweep이라는 방식으로 메모리에서 죽거나 오래된 객체를 가비지 컬렉팅 한다. 이 방법은, GC가 메모리 객체를 스캔하여 수집을 위해 '표시'하는 단계는 이를 작업하기 위해 실행을 일시 중지 시키기 때문에 다소 느리다.
그러나 V8은 점진적으로 최대한 많은 객체에 'mark'를 해두려고 한다. 수집이 끝날 때 까지, 전체 실행은 중단될 필요가 없기 때문에 빠르게 이뤄진다. 대용량 애플리케이션에서는, 이러한 성능의 향상이 많은 차이를 만든다.